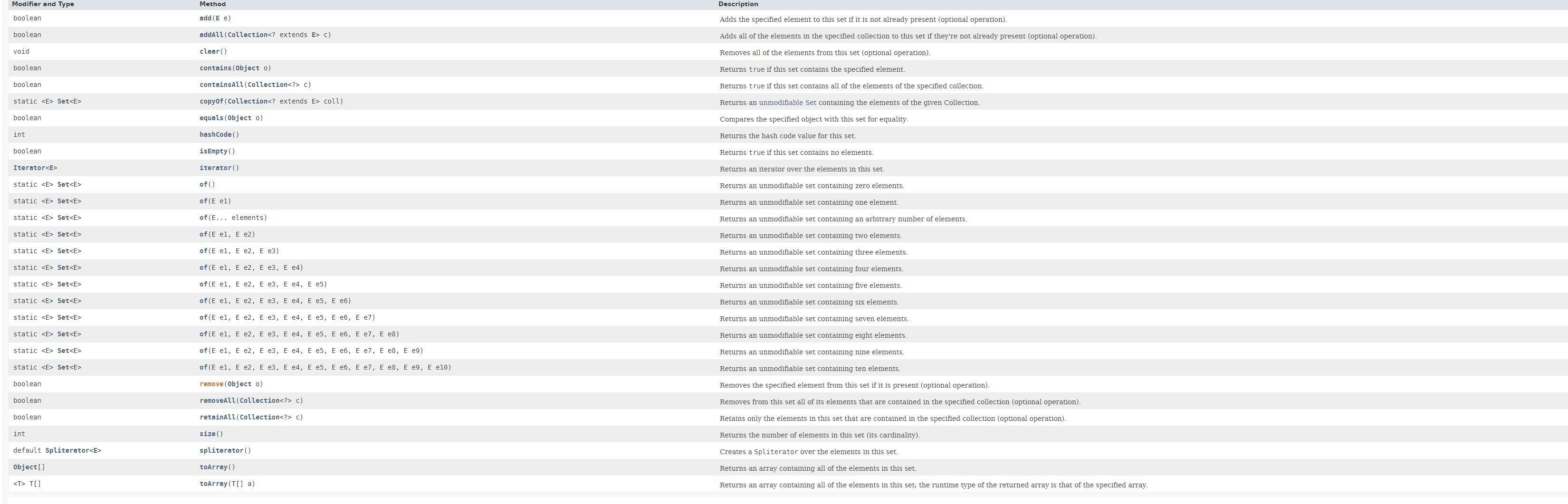
//jdk8加入的default //当不存在key返回defaultValue default V getOrDefault(Object key, V defaultValue){ V v; return (((v = get(key)) != null) || containsKey(key)) ? v : defaultValue; } //替代stream中的foreach,使用BiConsumer接口而不是Consumer defaultvoidforEach(BiConsumer<? super K, ? super V> action){ Objects.requireNonNull(action); for (Map.Entry<K, V> entry : entrySet()) { K k; V v; try { k = entry.getKey(); v = entry.getValue(); } catch (IllegalStateException ise) { // this usually means the entry is no longer in the map. thrownew ConcurrentModificationException(ise); } action.accept(k, v); } } //替换 defaultvoidreplaceAll(BiFunction<? super K, ? super V, ? extends V> function){ Objects.requireNonNull(function); for (Map.Entry<K, V> entry : entrySet()) { K k; V v; try { k = entry.getKey(); v = entry.getValue(); } catch (IllegalStateException ise) { // this usually means the entry is no longer in the map. thrownew ConcurrentModificationException(ise); }
// ise thrown from function is not a cme. v = function.apply(k, v);
try { entry.setValue(v); } catch (IllegalStateException ise) { // this usually means the entry is no longer in the map. thrownew ConcurrentModificationException(ise); } } } default V putIfAbsent(K key, V value){ V v = get(key); if (v == null) { v = put(key, value); }
return v; } //当key存在,并且对应的curValue==value时溢出,注意此处没有使用泛型 defaultbooleanremove(Object key, Object value){ Object curValue = get(key); if (!Objects.equals(curValue, value) || (curValue == null && !containsKey(key))) { returnfalse; } remove(key); returntrue; } //存在key,并且对应的curValue==oldValue是替换 defaultbooleanreplace(K key, V oldValue, V newValue){ Object curValue = get(key); if (!Objects.equals(curValue, oldValue) || (curValue == null && !containsKey(key))) { returnfalse; } put(key, newValue); returntrue; } //存在key就替换 default V replace(K key, V value){ V curValue; if (((curValue = get(key)) != null) || containsKey(key)) { curValue = put(key, value); } return curValue; } // 当key不存在时,调用mapper逻辑,替代stream中mapper()函数 default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction){ Objects.requireNonNull(mappingFunction); V v; if ((v = get(key)) == null) { V newValue; if ((newValue = mappingFunction.apply(key)) != null) { put(key, newValue); return newValue; } }
return v; } //当key存在时,根据key和value进行设置新值 default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction){ Objects.requireNonNull(remappingFunction); V oldValue; if ((oldValue = get(key)) != null) { V newValue = remappingFunction.apply(key, oldValue); if (newValue != null) { put(key, newValue); return newValue; } else { remove(key); returnnull; } } else { returnnull; } } //当存在旧值时,通过oldvalue和value进行创建新值并替换,否则newValue=vlaue,当newValue==null,移除该节点 default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction){ Objects.requireNonNull(remappingFunction); Objects.requireNonNull(value); V oldValue = get(key); V newValue = (oldValue == null) ? value : remappingFunction.apply(oldValue, value); if (newValue == null) { remove(key); } else { put(key, newValue); } return newValue; } /** jdk9新增 */ //返回不可修改视图,注意接口实现的static函数必须通过接口本身调用,Map.of 不能是HashMap.of static <K, V> Map<K, V> of(){ return ImmutableCollections.emptyMap(); } static <K, V> Map<K, V> of(K k1, V v1, K k2, V v2){ returnnew ImmutableCollections.MapN<>(k1, v1, k2, v2); } //.... Map中实现了多个该函数,类似于Set中
//通过enteries,放置多个, 看到entries就想起c++中的pair<>() static <K, V> Map<K, V> ofEntries(Entry<? extends K, ? extends V>... entries){ if (entries.length == 0) { // implicit null check of entries array return ImmutableCollections.emptyMap(); } elseif (entries.length == 1) { // implicit null check of the array slot returnnew ImmutableCollections.Map1<>(entries[0].getKey(), entries[0].getValue()); } else { Object[] kva = new Object[entries.length << 1]; int a = 0; for (Entry<? extends K, ? extends V> entry : entries) { // implicit null checks of each array slot kva[a++] = entry.getKey(); kva[a++] = entry.getValue(); } returnnew ImmutableCollections.MapN<>(kva); } } static <K, V> Entry<K, V> entry(K k, V v){ // KeyValueHolder checks for nulls returnnew KeyValueHolder<>(k, v); }
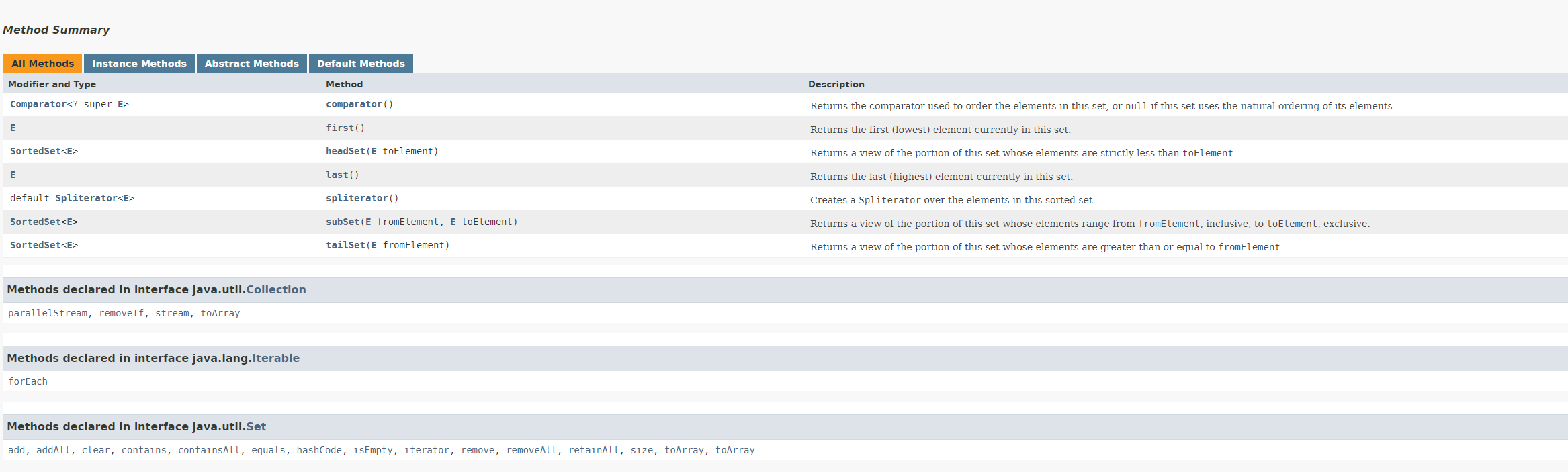
publicfinal V setValue(V newValue){ V oldValue = value; value = newValue; return oldValue; }
publicfinalbooleanequals(Object o){ if (o == this) returntrue; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) returntrue; } returnfalse; } }
publicinterfaceSpliterator<T> { booleantryAdvance(Consumer<? super T> action); //对当前元素进行action操作 defaultvoidforEachRemaining(Consumer<? super T> action){ do { } while (tryAdvance(action)); }//以当前位置迭代执行action } Spliterator<T> trySplit();//将Spliterator分割,这是该迭代器完成并发的关键
privateintgetFence(){ // initialize fence to size on first use int hi; // (a specialized variant appears in method forEach) if ((hi = fence) < 0) { //当第一次创建该迭代器时默认fence=-1,总之hi==边界fence expectedModCount = modCount; hi = fence = size; } return hi; } } public ArrayListSpliterator trySplit(){ int hi = getFence(), lo = index, mid = (lo + hi) >>> 1; //寻找当前位置----边界位置 >>>1 return (lo >= mid) ? null : // divide range in half unless too small new ArrayListSpliterator(lo, index = mid, expectedModCount); //创建一个分割的前半部分迭代器[lo,mid),当前迭代器变成[mid,fence) }
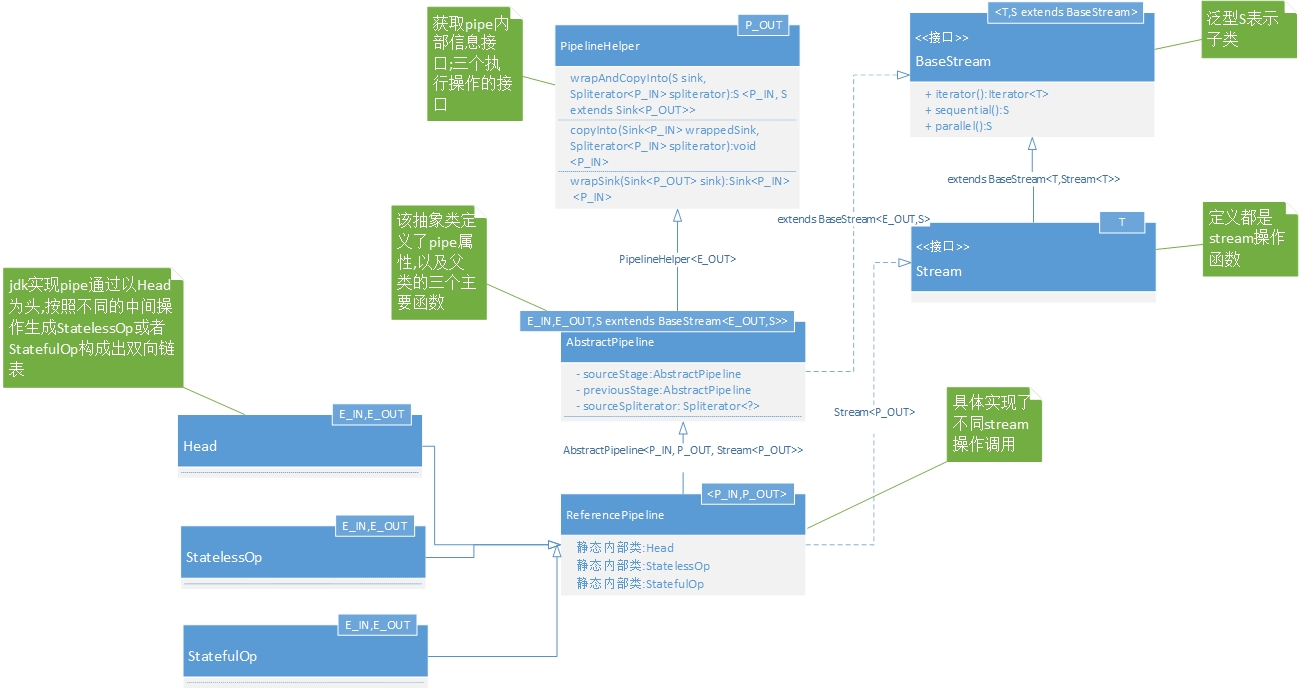
/** * Backlink to the head of the pipeline chain (self if this is the source * stage). */ @SuppressWarnings("rawtypes") privatefinal AbstractPipeline sourceStage; /** * The "upstream" pipeline, or null if this is the source stage. */ @SuppressWarnings("rawtypes") privatefinal AbstractPipeline previousStage;
/** * The operation flags for the intermediate operation represented by this * pipeline object. */ protectedfinalint sourceOrOpFlags;
/** * The next stage in the pipeline, or null if this is the last stage. * Effectively final at the point of linking to the next pipeline. */ @SuppressWarnings("rawtypes") private AbstractPipeline nextStage;
/** * The number of intermediate operations between this pipeline object * and the stream source if sequential, or the previous stateful if parallel. * Valid at the point of pipeline preparation for evaluation. */ privateint depth;
/** * The combined source and operation flags for the source and all operations * up to and including the operation represented by this pipeline object. * Valid at the point of pipeline preparation for evaluation. */ privateint combinedFlags;
/** * The source spliterator. Only valid for the head pipeline. * Before the pipeline is consumed if non-null then {@code sourceSupplier} * must be null. After the pipeline is consumed if non-null then is set to * null. */ private Spliterator<?> sourceSpliterator;
/** * The source supplier. Only valid for the head pipeline. Before the * pipeline is consumed if non-null then {@code sourceSpliterator} must be * null. After the pipeline is consumed if non-null then is set to null. */ private Supplier<? extends Spliterator<?>> sourceSupplier;
/** * True if this pipeline has been linked or consumed */ privateboolean linkedOrConsumed;
/** * True if there are any stateful ops in the pipeline; only valid for the * source stage. */ privateboolean sourceAnyStateful;
private Runnable sourceCloseAction;
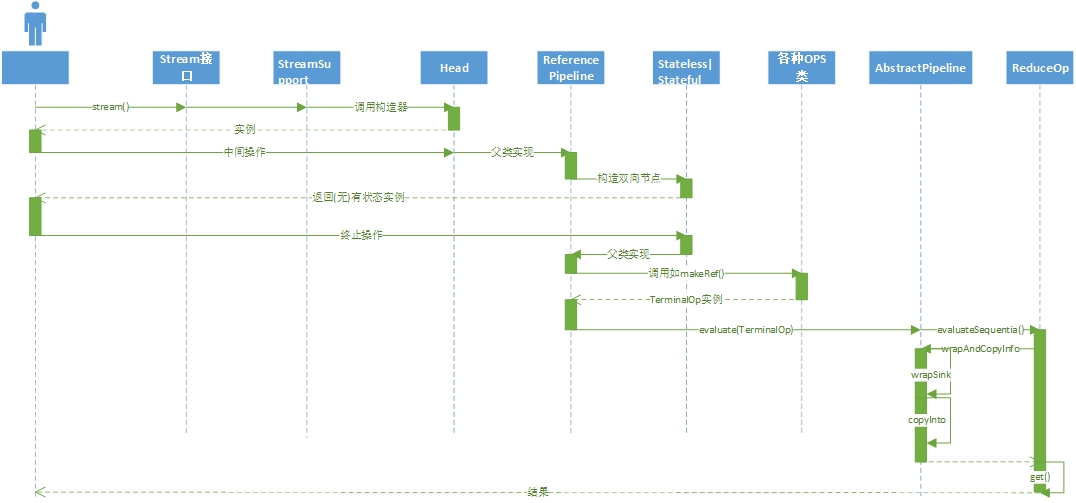
/** * True if pipeline is parallel, otherwise the pipeline is sequential; only * valid for the source stage. */ privateboolean parallel; /** * Constructor for the head of a stream pipeline. * * @param source {@code Supplier<Spliterator>} describing the stream source * @param sourceFlags The source flags for the stream source, described in * {@link StreamOpFlag} * @param parallel True if the pipeline is parallel */ AbstractPipeline(Supplier<? extends Spliterator<?>> source, int sourceFlags, boolean parallel) { this.previousStage = null; this.sourceSupplier = source; //不同的构造器区别在于源来自何处 this.sourceStage = this; this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK; // The following is an optimization of: // StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE); this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE; this.depth = 0; this.parallel = parallel; } AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) { this.previousStage = null; this.sourceSpliterator = source; //来自迭代器 this.sourceStage = this; this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK; // The following is an optimization of: // StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE); this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE; this.depth = 0; this.parallel = parallel; } AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) { if (previousStage.linkedOrConsumed) thrownew IllegalStateException(MSG_STREAM_LINKED); previousStage.linkedOrConsumed = true; previousStage.nextStage = this; //和上一个pipe连接
/** * Abstract {@code Sink} implementation designed for creating chains of * sinks. The {@code begin}, {@code end}, and * {@code cancellationRequested} methods are wired to chain to the * downstream {@code Sink}. This implementation takes a downstream * {@code Sink} of unknown input shape and produces a {@code Sink.OfLong}. * The implementation of the {@code accept()} method must call the correct * {@code accept()} method on the downstream {@code Sink}. */ abstractstaticclassChainedLong<E_OUT> implementsSink.OfLong{ protectedfinal Sink<? super E_OUT> downstream;
publicChainedLong(Sink<? super E_OUT> downstream){ this.downstream = Objects.requireNonNull(downstream); }
/** * Abstract {@code Sink} implementation designed for creating chains of * sinks. The {@code begin}, {@code end}, and * {@code cancellationRequested} methods are wired to chain to the * downstream {@code Sink}. This implementation takes a downstream * {@code Sink} of unknown input shape and produces a {@code Sink.OfDouble}. * The implementation of the {@code accept()} method must call the correct * {@code accept()} method on the downstream {@code Sink}. */ abstractstaticclassChainedDouble<E_OUT> implementsSink.OfDouble{ protectedfinal Sink<? super E_OUT> downstream;
publicChainedDouble(Sink<? super E_OUT> downstream){ this.downstream = Objects.requireNonNull(downstream); }
abstractstaticclassStatefulOp<E_IN, E_OUT> extendsReferencePipeline<E_IN, E_OUT> { /** * Construct a new Stream by appending a stateful intermediate operation * to an existing stream. * @param upstream The upstream pipeline stage * @param inputShape The stream shape for the upstream pipeline stage * @param opFlags Operation flags for the new stage */ StatefulOp(AbstractPipeline<?, E_IN, ?> upstream, StreamShape inputShape, int opFlags) { super(upstream, opFlags); assert upstream.getOutputShape() == inputShape; }